AI features are now standard product work. Recommendation engines, fraud detection, content moderation, and intelligent search ship on the same schedule, with the same stakeholder expectations, and under the same PM ownership as any other feature.
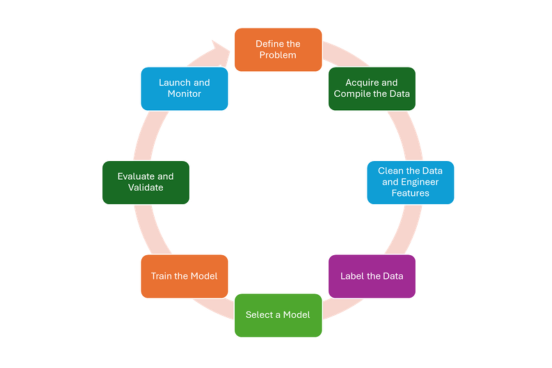
What is different is how you build them. The lifecycle that follows covers eight steps. They build on each other, but the path is not strictly linear. Training often reveals labeling problems. Evaluation often sends the team back to training. That is not a sign something went wrong. It is how AI development is supposed to work.
Understanding that terrain is part of the job. PMs who know what happens at each step can set accurate expectations with stakeholders, ask better questions of their engineering teams, and make informed trade-offs when timelines or outcomes need to change.
Step 1: Define the Problem

Start the same way you would with any other feature: understand the user problem clearly. What is the user experiencing? What does success look like from their perspective? The answers to those questions determine whether AI is the right tool. Some problems are better solved with a simpler approach. Others genuinely require a capability only AI can deliver.
Once the problem warrants AI, the next decision is whether to build a solution from scratch, fine-tune an existing one, or connect to a third-party service through an API. Building from scratch requires substantial data and significant engineering investment. Fine-tuning an existing model is a faster path when the problem is specialized but a general-purpose starting point is available. An API is the right choice when an off-the-shelf solution handles the problem well enough and building proprietary capability is not necessary. This is a product decision with real cost, timeline, and capability implications. It belongs here, before any data is acquired.
To make these decisions concrete, consider a team whose users are reporting that too much unwanted email is reaching their inbox. The volume and variety of spam makes this a reasonable candidate for AI. Spam patterns shift constantly, and a fixed rule set requires ongoing manual updates to stay effective. A system that learns from examples handles that variability better. On the build-vs-buy question, most teams in this situation would use a third-party API rather than build a custom solution. This example assumes a decision to build, which lets us walk through each step in full.
Step 2: Acquire and Compile the Data

Solving a problem with AI requires data, specifically historical examples of the problem you are trying to solve. The patterns connecting inputs to outcomes are learned from those examples, which makes the quality and coverage of the data foundational to everything that follows.
The first question is whether the data exists and whether you have access to it. Some data is already in your systems. Some needs to be collected, licensed, or generated. Two things determine whether it is adequate: volume and representativeness. A small dataset will not capture the range of variation in a real-world problem. A large dataset that covers only a narrow slice of the problem is equally limiting.
Acquiring data and having a usable dataset are not the same thing. Data comes from multiple sources in different formats, with different structures, and at different levels of quality. Compiling it means pulling everything together into something workable: reconciling formats, removing duplicates, and establishing a consistent structure. This is also where the first scope decisions get made. Not all available data belongs in the dataset. Data from a time period when the problem looked significantly different may introduce noise. Data from a different user type or product context may not reflect the users this solution will serve.
Before moving to the next step, the dataset needs to be split into three distinct sets: training data, a validation set, and a test set. The training data is what the model learns from. The validation set is used during training to detect when the model starts memorizing examples rather than learning from them. The test set is held out entirely and used only in the evaluation step to measure final performance. Mixing these up produces results that look strong in development and fall apart in production.
In the spam filter example, data comes from three sources: emails users have flagged as spam, emails caught by an existing rule-based filter, and a sample of emails users left in their inbox. These are pulled into a single dataset with a consistent structure: email content, sender information, header metadata, and whether each email was marked as spam. Older emails from periods when spam patterns looked materially different are candidates for exclusion. The validation set is drawn from a later time period than the main training data so it reflects more recent patterns.
Step 3: Clean the Data

This step covers two related activities: cleaning the data and engineering the features the model will actually learn from. It tends to take longer than teams expect, and it is not always visible to stakeholders. Teams that are behind schedule on an AI feature are often behind here.
Cleaning the data means resolving the problems that would corrupt what the model learns. Missing values, inconsistent formatting, and mixed data structures all need to be resolved before training begins. Incorrect classifications are the most consequential problem. If the existing classifications in the dataset are wrong in systematic ways, those errors get absorbed and the system learns the wrong patterns. Reviewing a random sample before proceeding is a basic check that catches problems a script will not find.
Feature engineering is the process of transforming raw data into the specific inputs the model will use to learn. It runs alongside cleaning, because decisions about what to clean depend on knowing what you are trying to extract. The question to ask is: what information would a human expert use to make this judgment? The answers become candidates for features. Decisions made here, which attributes to include, how to represent them, and which to discard, directly shape what the model is capable of learning. A model cannot compensate for features that were poorly constructed or left out entirely.
Step 4: Label the Data

Labeling is the process of assigning the correct answer to each example in the dataset. For the spam filter, that means confirming each email is correctly marked as spam or not spam. Some of this work happened during data cleaning when existing classifications were reviewed and corrected. A dedicated labeling pass is often still necessary, particularly when existing classifications are incomplete or were assigned by a prior system that made errors.
For large datasets, labeling is done by annotators working from a guide that defines exactly what qualifies as each category. Consistency across annotators matters. If two people working from the same guide regularly disagree on how to classify an example, the guide needs to be refined before labeling continues.
The quality of the labels sets the ceiling on what the system can learn. It cannot learn the right patterns from incorrectly labeled examples.
Step 5: Select a Model

A model is the mechanism that learns from labeled data and makes predictions. Different problems call for different models, and the choice comes down to the type of output the problem requires, the nature of the data, and what the labeled examples actually look like.
Product managers do not need to make this decision unilaterally, but understanding the trade-offs is part of the job. The most sophisticated model is not always the right one. A simpler model that hits the accuracy threshold is easier to interpret, easier to debug when it fails, and faster to iterate on.
For the spam filter, the natural starting candidates are Naive Bayes, Logistic Regression, and Support Vector Machines. Naive Bayes is the right place to start: it trains quickly, handles text well, and has a long track record for this type of problem. If it does not meet the accuracy threshold, Logistic Regression and Support Vector Machines are the natural next steps, each better suited to cases where the simpler approach keeps making the same mistakes.
Step 6: Train the Model

Training is the process of running the labeled dataset through the selected model so it can learn the patterns connecting inputs to outcomes. Two concepts matter here.
Hyperparameter tuning involves setting the configuration parameters that govern how the model learns. These are set before training begins, not learned from the data. Getting them wrong produces a model that is either too rigid to detect real patterns or too sensitive and starts picking up noise.
Overfitting happens when the model memorizes the training data rather than learning from it. It performs well on examples it has seen and poorly on ones it has not. The primary defenses are keeping the model appropriately simple and monitoring performance against the validation set during training to catch the point where performance on new examples starts to degrade.
Step 7: Evaluate and Validate

Training produces a model. This step determines whether that model is ready to ship.
Evaluation means testing the model against the held-out test set, data that was never used in training or hyperparameter tuning. The metrics should have been defined when the problem was defined in Step 1. For the spam filter, accuracy alone is insufficient. A model that classifies every email as legitimate would score well on accuracy if spam makes up a small fraction of total volume, but it would be useless. The metrics that matter are precision, recall, and the false positive rate. A spam filter that blocks legitimate email causes direct harm to users, which makes false positives the failure mode to weight most heavily.
Validation goes further than aggregate metrics. It examines where the model fails and whether those failures are acceptable. Checking performance across different user segments, email types, and time periods reveals whether the model generalizes or only performs well under conditions that were well-represented in the training data. Edge cases, the examples the model is least confident about, deserve specific attention. They are the ones most likely to generate complaints in production.
Latency is also validated here. The model needs to respond at the speed the product requires. A spam filter that introduces meaningful delay into email delivery is not acceptable regardless of its accuracy. If it cannot meet the latency requirement, that is a reason to go back, the same as failing an accuracy threshold.
If the model does not meet the defined thresholds, the right response is to go back. Depending on what the evaluation reveals, that might mean retraining with adjusted hyperparameters, revisiting the labeling for problem areas, or going further back to examine whether the training data adequately covers the cases where the model is failing. This is a normal part of the process.
Step 8: Launch and Monitor

Launch is where the solution is integrated into the application. The model begins receiving real inputs and its outputs drive actual behavior. For the spam filter, that means incoming emails are scored and routed in real time.
A phased rollout, starting with a subset of users or a shadow mode where outputs are logged but not acted on, gives the team the opportunity to catch problems before they affect everyone and to confirm that the improvement measured in evaluation holds in production.
The launch plan needs to account for what happens when the model is wrong. No model is perfect. For the spam filter, that means giving users a way to report misclassified emails and capturing those reports systematically.
Those reports feed directly into what comes after launch: ongoing monitoring and periodic retraining. This is not optional maintenance work. It is a core operational responsibility that needs to be planned and resourced before the feature ships.
Monitoring means tracking the same metrics used in evaluation against production traffic on a defined schedule. Model performance degrades over time as the inputs encountered in production diverge from the data the model was trained on. This is called data drift, and it is not a sign the model was built poorly. It is an expected consequence of a changing environment. For the spam filter, spam patterns evolve continuously. A model that is not updated on new examples will gradually become less effective regardless of how well it performed at launch.
Retraining means periodically incorporating new labeled examples into the training data and running the model through the process again. How often this needs to happen depends on how quickly the problem evolves. Some models can run for months without meaningful degradation. Others need updates on a shorter cycle. The only way to know is to monitor.
The implication for roadmap planning is direct. A team that launches an AI feature without allocating ongoing capacity for monitoring and retraining has not finished the work. They have taken on a recurring operational commitment that will surface as unplanned work if it is not treated as planned work from the start.


